[R-bloggers] Building a Shiny App as a Package (and 14 more aRticles) |  |
- Building a Shiny App as a Package
- Machine Learning explained for statistics folk
- Spatial data and maps conference – FOSS4G
- The Rich didn’t earn their Wealth, they just got Lucky
- Google Next 2019 – observations from the Mango viewing deck
- Zooming in on maps with sf and ggplot2
- RcppArmadillo 0.9.400.2.0
- Could not Resist
- RStudio 1.2 Released
- ViennaR Meetup March – Full Talks Online
- Relaunching the qualtRics package
- Relaunching the qualtRics package
- What matters more in a cluster randomized trial: number or size?
- Compute R2s and other performance indices for all your models!
- Marketing with Machine Learning: Apriori
| Building a Shiny App as a Package Posted: 30 Apr 2019 07:24 AM PDT (This article was first published on (en) The R Task Force, and kindly contributed to R-bloggers) Shiny App as a PackageIn a previous post, I've introduced the But, in a world where Shiny Applications are mostly created as a series of files, why bother with a package? This is the question I'll be focusing on in this blog post. What's in a Shiny App?OK, so let's ask the question the other way round. Think about your last Shiny which was created as a single-file ( So, let's have a review of what you'll need next for a robust application. First, metadata. In other words, the name of the app, the version number (which is crucial to any serious, production-level project), what the application does, who to contact if something goes wrong. Then, you need to find a way to handle the dependencies. Because you know, when you want to push your app into production, you can't have this conversation with IT:
So yes, dependencies matter. You need to handle them, and handle them correctly. Now, let's say you're building a big app. Something with thousands of lines of code. Handling a one-file or two-file shiny app with that much lines is just a nightmare. So, what to do? Let's split everything into smaller files that we can call! And finally, we want our app to live long and prosper, which means we need to document it: each small pieces of code should have a piece of comment to explain what these specific lines do. The other thing we need for our application to be successful on the long run is tests, so that we are sure we're not introducing any regression. Oh, and that would be nice if people can get a OK, so let's sum up: we want to build an app. This app needs to have metadata and to handle dependencies corrrecly, which is what you get from the The other plus side of Shiny as a PackageTestingNothing should go to production without being tested. Nothing. Testing production apps is a wide question, and I'll just stick to tests inside a Package here. Frameworks for package testing are robust and widely documented. So you don't have to put any extra-effort here: just use a canonical testing framework like What should you test?
This can for example be useful if you need to test a module. A UI module function returns an HTML tag list, so once your modules are set you can save them and use them inside tests.
Note: this specific configuration will possibly fail on Continuous integration platform as Gitlab CI or Travis. A workaround is to, inside your CI yml, first install the package with For example:
DocumentingDocumenting packages is a natural thing for any R developer. Any exported function should have its own documentation, hence you are "forced" to document any user facing-function. Also, building a Shiny App as a package allows you to write standard R documentation:
DeployLocal deploymentAs your Shiny App is a standard package, it can be built as a to launch your app. RStudio Connect & Shiny ServerBoth these platforms expect a file app configuration, i.e an
And of course, don't forget to list this file in the This is the file you'll get if your run Docker containersIn order to dockerize your app, simply install the package as any other package, and use as a You'll get the Dockerfile you need with Resources
The post Building a Shiny App as a Package appeared first on (en) The R Task Force.
To leave a comment for the author, please follow the link and comment on their blog: (en) The R Task Force. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Machine Learning explained for statistics folk Posted: 30 Apr 2019 06:58 AM PDT (This article was first published on R – Dataviz – Stats – Bayes, and kindly contributed to R-bloggers) I'm running a one-day workshop called "From Statistics To Machine Learning" in central London on 28 October, for anyone who learnt some statistics and wants to find out about machine learning methods. I guess you might feel frustrated. There's a lot of interest and investment in machine learning, but it's hard to know where to start learning if you have a stats background. Writing is either aimed squarely at experts in computer science, with a lot of weird jargon that looks almost familiar, but isn't quite (features? loss functions? out-of-bag?), or is written for gullible idiots with more money than sense. This workshop is a mixture of about 25% talks, 25% demonstration with R, and 50% small-group activities where you will consider scenarios detailing realistic data analysis needs for public sector, private sector and NGOs. Your task will be to discuss possible machine learning approaches and to propose an analysis plan, detailing pros and cons and risks to the organisation from data problems and unethical consequences. You'll also have time to practice communicating the analysis plan in plain English to decision-makers. With only 18 seats, it'll be a small enough session for everyone to learn from each other and really get involved. This is not one where you sit at the back and catch up on your emails! I've built this out of training I've done for clients who wanted machine learning and AI demystified. The difference here is that you're expected to have some statistical know-how, so we can start talking about the strengths and weaknesses of machine learning in a rigorous way that is actually useful to you in your work straight away. Here are some topics we'll cover:
You can bring a laptop to try out some of the examples in R, but this is not essential. It's £110 all inclusive, which is about as cheap as I can make it with a central London venue. I'm mindful that a lot of people interested in this might be students or academics or public sector analysts, and I know you don't exactly have big training budgets to dip into. Having said that, you can haggle with me if you're a self-funding student or out of work or whatever. Venue is TBC but I'll confirm soon. If I get my way it'll be one where you get breakfast (yes!), bottomless coffee and tea (yes!!) and a genuinely nice lunch (yes!!!), all included in the cost. Then, we can repair to the craft beer company afterwards and compare laptop stickers. Book 'em quick here! I've had a lot of interest in this and it might go fast.
To leave a comment for the author, please follow the link and comment on their blog: R – Dataviz – Stats – Bayes. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... |
| Spatial data and maps conference – FOSS4G Posted: 30 Apr 2019 03:36 AM PDT (This article was first published on R – scottishsnow, and kindly contributed to R-bloggers) I'm helping organise a conference on (geo)spatial open source software – FOSS4G. We're hosting it in the great city of Edinburgh, Scotland in September 2019. Abstract submissions: https://uk.osgeo.org/foss4guk2019/talks_workshops.html We're very interested in hearing your tales of R, QGIS, Python, GRASS, PostGIS, etc.!
To leave a comment for the author, please follow the link and comment on their blog: R – scottishsnow. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... |
| The Rich didn’t earn their Wealth, they just got Lucky Posted: 30 Apr 2019 03:00 AM PDT (This article was first published on R-Bloggers – Learning Machines, and kindly contributed to R-bloggers)
A few months ago I posted a piece with the title "If wealth had anything to do with intelligence…" where I argued that ability, e.g. intelligence, as an input has nothing to do with wealth as an output. It drew a lot of criticism (as expected), most of it unfounded in my opinion but one piece merits some discussion: the fact that the intelligence quotient (IQ) is normally distributed by construction. The argument goes that intelligence per se may be a distribution with fat tails too but by the way the IQ is constructed the metric is being transformed into a well formed gaussian distribution. To a degree this is certainly true, yet I would still argue that the distribution of intelligence and all other human abilities are far more well behaved than the extremely unequal distribution of wealth. I wrote in a comment:
So, if you have a source, Dear Reader, you are more than welcome to share it in the comments – I am always eager to learn! I ended my post with:
In this post I will argue that luck is a good candidate, so read on…
In 2014 there was a special issue of the renowned magazine Science titled "The science of inequality". In one of the articles (Cho, A.: "Physicists say it's simple") the following thought experiment is being proposed:
So, the basic idea is to randomly throw 9,999 darts at a scale ranging from zero to 500 million and study the resulting distribution of intervals: library(MASS) w <- 5e8 # wealth p <- 1e4 # no. of people set.seed(123) d <- diff(c(0, sort(runif(p-1, max = w)), w)) # wealth distribution h <- hist(d, col = "red", main = "Exponential decline", freq = FALSE, breaks = 45, xlim = c(0, quantile(d, 0.99))) fit <- fitdistr(d, "exponential") curve(dexp(x, rate = fit$estimate), col = "black", type = "p", pch = 16, add = TRUE)
The resulting distribution fits an exponential distribution very well. You can read some interesting discussions concerning this result on CrossValidated StackExchange: How can I analytically prove that randomly dividing an amount results in an exponential distribution (of e.g. income and wealth)? Just to give you an idea of how unfair this distribution is: the richest six persons have more wealth than the poorest ten percent together: sum(sort(d)[9994:10000]) - sum(sort(d)[0:1000]) ## [1] 183670.8 If you think that this is ridiculous just look at the real global wealth distribution: here it is not six but three persons who own more than the poorest ten percent! Now, what does that mean? Well, equality seems to be the exception and (extreme) inequality the rule. The intervals were found randomly, no interval had any special skills, just luck – and the result is (extreme) inequality – as in the real world! If you can reproduce the wealth distribution of a society stochastically this could have the implication that it weren't so much the extraordinary skills of the rich which made them rich but they just got lucky. Some rich people are decent enough to admit this. In his impressive essay "Why Poverty Is Like a Disease" Christian H. Cooper, a hillbilly turned investment banker writes:
A consequence would be that you cannot really learn much from the rich. So throw away all of your self help books on how to become successful. I will end with a cartoon, which brings home this message, on a closely related concept, the so called survivorship bias (which is also important to keep in mind when backtesting trading strategies in quantitative finance, the topic of an upcoming post… so stay tuned!): 
To leave a comment for the author, please follow the link and comment on their blog: R-Bloggers – Learning Machines. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Google Next 2019 – observations from the Mango viewing deck Posted: 30 Apr 2019 02:01 AM PDT (This article was first published on RBlog – Mango Solutions, and kindly contributed to R-bloggers) The first thing that hit me about this year's Google Next was the scale. Thousands of people wandering around Moscone Centre in San Fran with their name badges proudly displayed really brought home that this is a platform of which its users are proud. I was told by several people that the size of the conference has doubled in size year on year, which, given there were 35,000 people at this year's event, may well prove a logistical nightmare next year. I was really struck by the massive enthusiasm of the Google team, the way in which the company's leadership is aware of Google's market position and how they seem to be keen to take pragmatic and strategic decisions based on where they are, versus where they might like to be. The opening up to other cloud platforms via the Anthos announcement seems a good way for Google to position itself as the honest broker in the field – they have identified legacy apps and codebases as difficult to turnover, something which I think many organisations will feel comfortable. There were rafts of customer testimonials and whilst many of them did not seem to contain much in the way of ROI details, the mere fact that Google could call these C-level Fortune 500 companies onto the stage speaks towards a clarity of intent and purpose. The nature of many of these types of events is one that is fairly broad, and considering that Mango is a relatively niche player, it is sometimes difficult to find the areas and talks that may resonate with our posture. That was true of these sessions., but not entirely surprising. The widescale abuse of terms like AI and Machine Learning carries on apace, and we at Mango need to find ways to gently persuade people that when they think of AI, they're actually meaning Machine Learning, and when they talk about Machine Learning they might well be talking about, well, models. The current push in the industry is to be able to add these complex components at a click of a button, by an untrained analyst who can then roll it into production without proper validation or testing. These are dangerous situations and reminded me of the importance of doing some of the hard yards first i.e creating an analytic culture and community to ensure that the "right" analytics are used with the "right" data. It's clear however that the opening up of cloud platforms is creating an arena in which advanced analytics will play a crucial role, and presents massive opportunities for Mango in working with Google and our customers. We've loved being back in San Francisco and its always lovely to be around passionate and energetic advocates. Hopefully London Next later in the year will be equally energetic and fun.
To leave a comment for the author, please follow the link and comment on their blog: RBlog – Mango Solutions. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Zooming in on maps with sf and ggplot2 Posted: 30 Apr 2019 01:58 AM PDT (This article was first published on r-bloggers – WZB Data Science Blog, and kindly contributed to R-bloggers) When working with geo-spatial data in R, I usually use the sf package for manipulating spatial data as Simple Features objects and ggplot2 with
I will show the advantages and disadvantages of these options and especially focus on how to zoom in on a certain point of interest at a specific "zoom level". We will see how to calculate the coordinates of the display window or "bounding box" around this zoom point.
Loading the required libraries and dataWe'll need to load the following packages: Using We see that we have a spatial dataset consisting of several attributes (only Let's plot this data to confirm what we have:
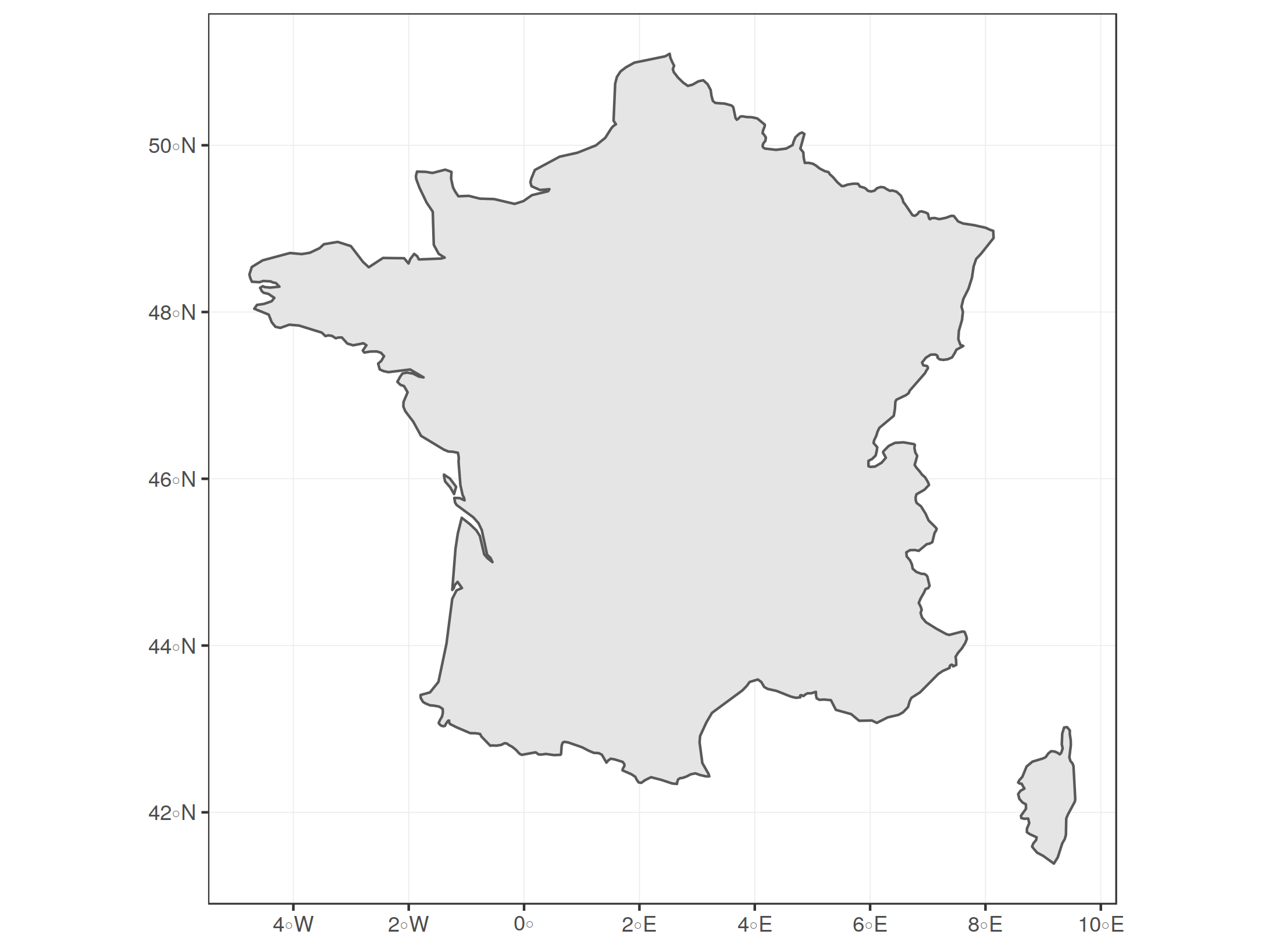
Selecting certain areas of interest from a spatial datasetThis is quite straight forward: We can plot a subset of a larger spatial dataset and then ggplot2 automatically sets the display window accordingly, so that it only includes the selected geometries. Let's select and plot France only:
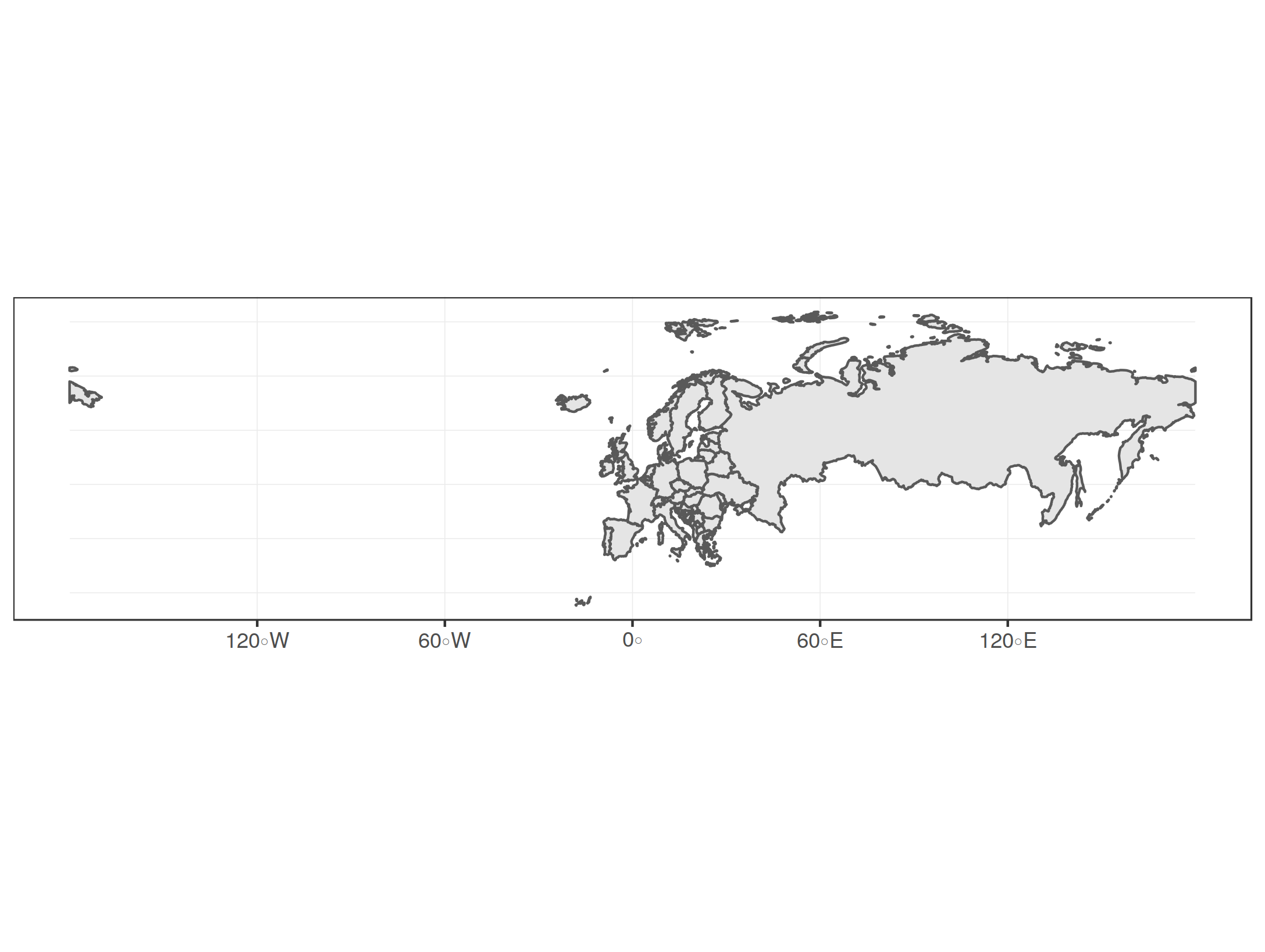
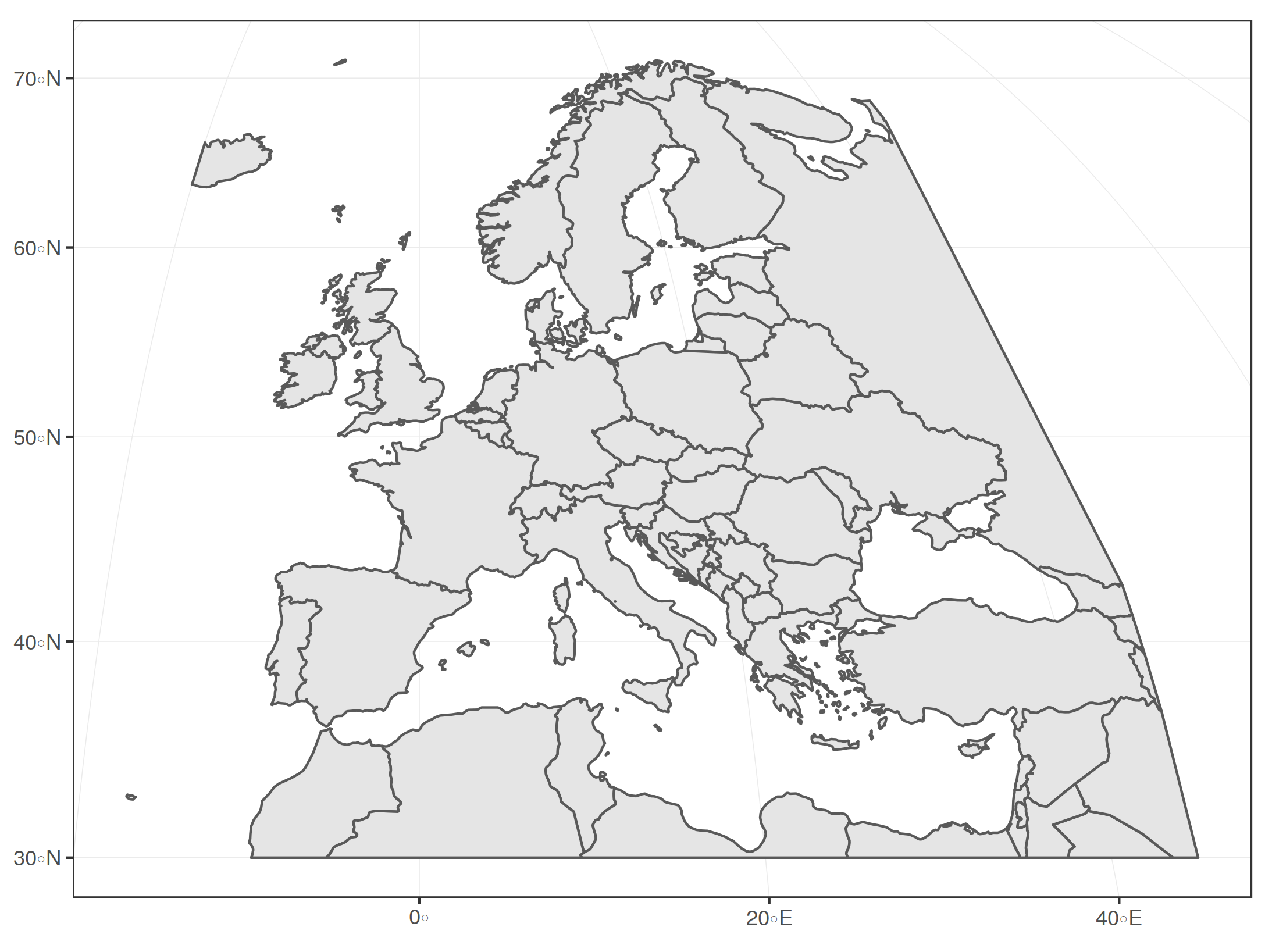
Let's try to select and plot all countries from Europe:
Well, this is probably not the section that you want to display when you want to make a plot of Europe. It includes whole Russia (since its Cropping geometries in the spatial dataset or restricting the display windowTo fix this, you may crop the geometries in your spatial dataset as if you took a knife a sliced through the shapes on the map to take out a rectangular region of interest. The alternative would be to restrict the display window of your plot, which is like taking the map and folding it so that you only see the region of interest. The rest of the map still exists, you just don't see it. So both approaches are quite similar, only that the first actually changes the data by cutting the geometries, whereas the latter only "zooms" to a detail but keeps the underlying data untouched. Let's try out the cropping method first, which can be done with
You can see that the shapes were actually cropped at the specified ranges when you look at the gaps near the plot margins. If you want to remove these gaps, you can add We can also see that we now have clipped shapes when we project them to a different CRS. We can see that in the default projection that is used by ggplot2, the grid of longitudes and latitudes, which is called graticule, is made of perpendicular lines (displayed as light gray lines). When we use a Mollweide projection, which is a "pseudo-cylindrical" projection, we see how the clipped shapes are warped along the meridians, which do not run in parallel in this projection but converge to the polar ends of the prime meridian:
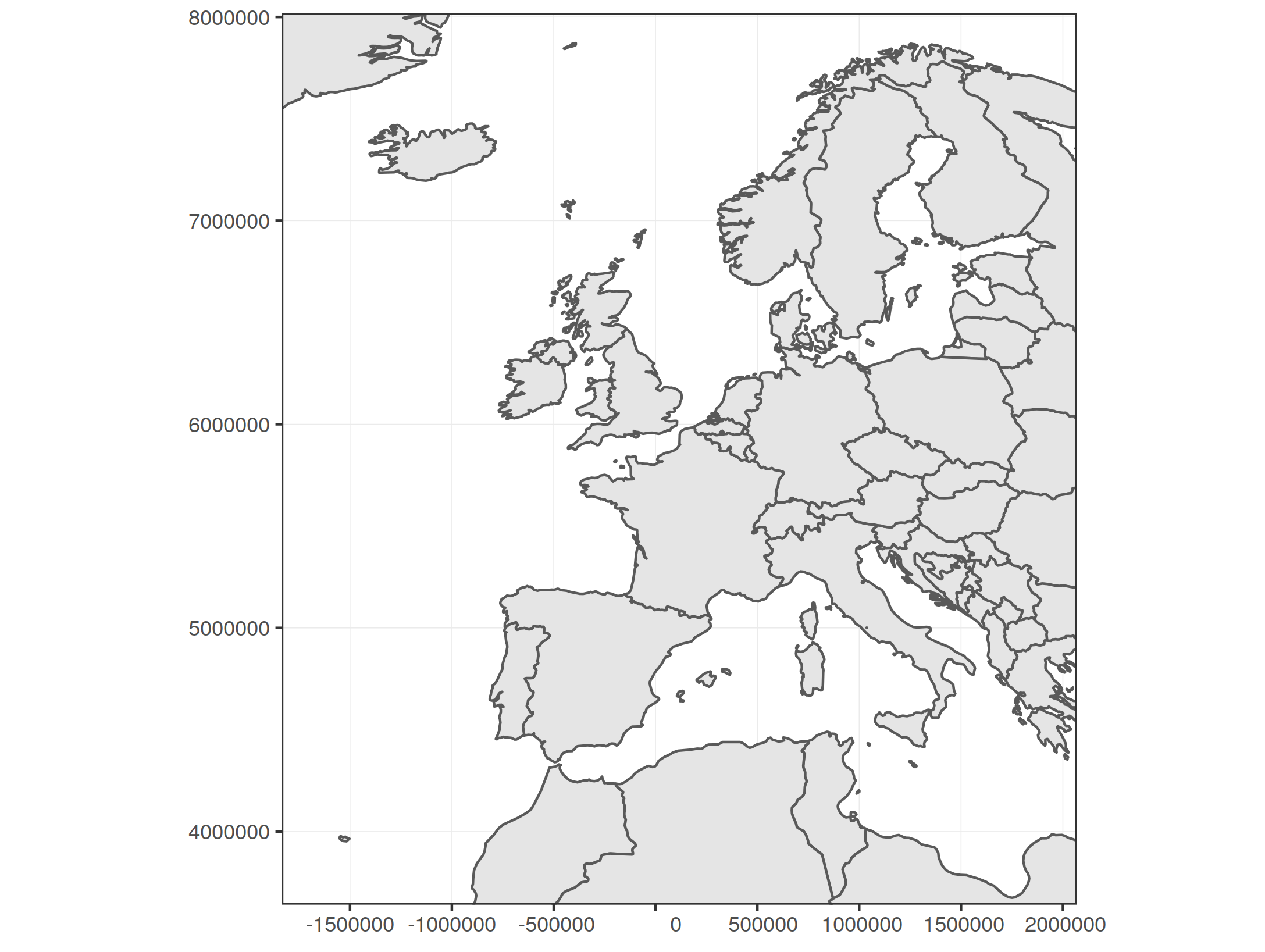
Restricting the display window for plotting achieves a very similar result, only that we don't need to modify the spatial dataset. We can use
You see that the result is very similar, but we use the whole Now what if we wanted to use the Mollweide projection again as target projection for this section? Let's try:
What happened here? The problem is that we specified So in order to fix that, we'd need to transform the coordinates of the display window to the target CRS first. First, let's get a visual overview on what we want to do:
What we see is the whole At first, we set the target CRS and transform the whole Next, we specify the display window in WGS84 coordinates as longitude / latitude degrees. We only specify the bottom left and top right corners (points A and B). The CRS is set to WGS84 by using the EPSG code 4236. These coordinates can be transformed to our target CRS via We can extract the coordinates from these points and pass them as limits for the x and y scale respectively. Note also that I set
This works, but if you look closely, you'll notice that the display window is slightly different than the one specified in WGS84 coordinates before (the red trapezoid). For example, Turkey is completely missing. This is because the coordinates describe the rectangle between A and B in Mollweide projection, and not the red trapezoid that comes from the original projection. Calculating the display window for given a center point and zoom levelInstead of specifying a rectangular region of interest, I found it more comfortable to set a center point of interest and specify a "zoom level" which specifies how much area around this spot should be displayed. I oriented myself on how zoom levels are defined for OpenStreetMap: A level of zero shows the whole world. A level of 1 shows a quarter of the world map. A level of two shows 1/16th of the world map and so on. This goes up to a zoom level of 19. So if Let's set a center point Now we can calculate the longitude and latitude ranges for the the display window by subtracting/adding the half of the above ranges from/to the zoom center coordinates respectively. We can now plot the map with the specified display window for zoom level 3, highlighting the zoom center as red dot:
So this works quite good when using the default projection and WGS84 coordinates. How about another projection? Let's put Kamchatka at the center of our map, set a zoom level, and use a Lambert azimuthal equal-area projection (LAEA) centered at our zoom point: When we worked with WGS84 coordinates before, we calculated the displayed range of longitude and latitude at a given zoom level We can now calculate the lower left and upper right corner of our display window as before, by subtracting/adding half of Rounding errors aside, this confirms that the zoom point is at the center of projection. We can now calculate the display window coordinates as stated before¹: And now passing the display window coordinates to
You can try this out with different zoom levels, zoom center points and projections. Note that some combinations of zoom levels and projections will cause projection errors, since some projection are only specified within certain bounds and not for the whole world. I put the full R script in this gist. ¹ Again, we could simplify this in the special case where the zoom point is the center of projection. Also note that I had to wrap each coordinate in
To leave a comment for the author, please follow the link and comment on their blog: r-bloggers – WZB Data Science Blog. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Posted: 29 Apr 2019 06:59 PM PDT (This article was first published on Thinking inside the box , and kindly contributed to R-bloggers)
A new RcppArmadillo release based on the very recent Armadillo upstream release arrived on CRAN earlier today, and will get to Debian shortly. Armadillo is a powerful and expressive C++ template library for linear algebra aiming towards a good balance between speed and ease of use with a syntax deliberately close to a Matlab. RcppArmadillo integrates this library with the R environment and language–and is widely used by (currently) 587 other packages on CRAN. The (upstream-only again this time) changes are listed below:
Courtesy of CRANberries, there is a diffstat report relative to previous release. More detailed information is on the RcppArmadillo page. Questions, comments etc should go to the rcpp-devel mailing list off the R-Forge page. This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
To leave a comment for the author, please follow the link and comment on their blog: Thinking inside the box . R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Posted: 29 Apr 2019 05:21 PM PDT (This article was first published on R – Win-Vector Blog, and kindly contributed to R-bloggers)
Also, Practical Data Science with R, 2nd Edition; Zumel, Mount; Manning 2019 is now content complete! It is deep into editing and soon into production!
To leave a comment for the author, please follow the link and comment on their blog: R – Win-Vector Blog. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on RStudio Blog, and kindly contributed to R-bloggers)
We're excited to announce the official release of RStudio 1.2! What's new in RStudio 1.2?Over a year in the making, this new release of RStudio includes dozens of new productivity enhancements and capabilities. You'll now find RStudio a more comfortable workbench for working in SQL, Stan, Python, and D3. Testing your R code is easier, too, with integrations for shinytest and testthat. Create, and test, and publish APIs in R with Plumber. And get more done with background jobs, which let you run R scripts while you work. Underpinning it all is a new rendering engine based on modern Web standards, so RStudio Desktop looks sharp on displays large and small, and performs better everywhere – especially if you're using the latest Web technology in your visualizations, Shiny applications, and R Markdown documents. Don't like how it looks now? No problem–just make your own theme. You can read more about what's new this release in the release notes, or our RStudio 1.2 blog series. Thank you!We'd like to thank the open source community for helping us to make this release possible. Many of you used the preview releases for your day to day work and gave us invaluable bug reports, ideas, and feedback. We're grateful for your support–thank you for helping us to continue making RStudio the best workbench for data science! All products based on RStudio have been updated. You can download the new release, RStudio 1.2.1335, here: Feedback on the new release is always welcome in the community forum. Update and let us know what you think! Coming Soon: RStudio Pro 1.2 General Availability announcement
To leave a comment for the author, please follow the link and comment on their blog: RStudio Blog. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| ViennaR Meetup March – Full Talks Online Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on Quantargo Blog, and kindly contributed to R-bloggers) The full talks of the ViennaR March Meetup are finally online: A short Introduction to ViennaR, Laura Vana introducing R-Ladies Vienna and Hadley Wickham with a great introduction to tidy(er) data and the new functions IntroductionYou can download the slides of the introduction here. Laura Vana: R-LadiesLaura introduced the R-Ladies Vienna – a program initiated by the R-Consortium to
from https://rladies.org. Visit the Meetup site to find out more about upcoming R-Ladies events including workshops covering an R Introduction and Bayesian Statistics. Hadley Wickham: Tidy(er) DataHadley Wickham's talk covered the tidyr package and two new functions:
To leave a comment for the author, please follow the link and comment on their blog: Quantargo Blog. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Relaunching the qualtRics package Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on Rstats on Julia Silge, and kindly contributed to R-bloggers) Note: cross-posted with the rOpenSci blog. rOpenSci is one of the first organizations in the R community I ever interacted with, when I participated in the 2016 rOpenSci unconf. I have since reviewed several rOpenSci packages and been so happy to be connected to this community, but I have never submitted or maintained a package myself. All that changed when I heard the call for a new maintainer for the qualtRics package. "IT'S GO TIME," I thought. Qualtrics is an online survey and data collection software platform. Qualtrics is used across many domains in both academia and industry for online surveys and research, including by me at my day job as a data scientist at Stack Overflow. While users can manually download survey responses from Qualtrics through a browser, importing this data into R is then cumbersome. The qualtRics R package implements the retrieval of survey data using the Qualtrics API and aims to reduce the pre-processing steps needed in analyzing such surveys. This package has been a huge help to me in my real day-to-day work, and I have been so grateful for the excellent work of the package's original authors, including the previous maintainer Jasper Ginn. This package is currently the only package on CRAN that offers functionality like this for Qualtrics' API, and is included in the official Qualtrics API documentation. The previous maintainer of this package was no longer using Qualtrics in his work life and needed to step away from maintaining qualtRics. Also, early in 2018, the package had been archived on CRAN for a fairly minor issue: using testthat for tests but not having it included in Qualtrics and the Stack Overflow Developer SurveyThe timing of when I did the usability work for this package was either wonderful or terrible, depending on your perspective. I did that work concurrently with the analysis for the 2019 Stack Overflow Developer Survey. This survey is the largest and most comprehensive survey of people who code around the world each year, and this year we had almost 90,000 respondents who answered questions covering everything from their favorite technologies to what music they listen to while coding. The survey is fielded using Qualtrics and I've used the qualtRics package for the past several years as part of my workflow. This year, I made changes to the package while I was working with the Developer Survey data. I'll be honest; it was… A LOT to juggle at one time. After the bulk of my analysis work was done for the survey, I turned to getting qualtRics back on CRAN. The previous maintainer, who has been unfailingly helpful throughout this process, sent an email to CRAN with the details involved (his name, my name, the fact of the package's archiving). Then I submitted the package to CRAN, basically as if it were a new package. I got some feedback back from CRAN initially, to use more single quotes in GOOD IDEA/BAD IDEAChanging the names of all the functions in a package already being used in the real world is, generally, a bad idea. I did it anyway, everybody. Let me try to convince you that this was the right call.
The old versions of the functions currently still work but give a warning, suggesting that the user try out the new versions. If this change causes more than a passing inconvenience to you as a user, I AM SO SORRY. I believe this decision will set up the qualtRics package for improved usability in the long term. Explore the new qualtRics!Another change with this release is a pkgdown site for qualtRics. I used the custom pkgdown template rotemplate created for rOpenSci packages to style the site, and I am so pleased with the results! If you are a new user for the qualtRics package, or someone who wants to poke around and see what's changed and how to get up to speed with the update, I recommend checking out this spiffy new site for all the details.
To leave a comment for the author, please follow the link and comment on their blog: Rstats on Julia Silge. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Relaunching the qualtRics package Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on rOpenSci - open tools for open science, and kindly contributed to R-bloggers) rOpenSci is one of the first organizations in the R community I ever interacted with, when I participated in the 2016 rOpenSci unconf. I have since reviewed several rOpenSci packages and been so happy to be connected to this community, but I have never submitted or maintained a package myself. All that changed when I heard the call for a new maintainer for the qualtRics package. "IT'S GO TIME," I thought. Qualtrics is an online survey and data collection software platform. Qualtrics is used across many domains in both academia and industry for online surveys and research, including by me at my day job as a data scientist at Stack Overflow. While users can manually download survey responses from Qualtrics through a browser, importing this data into R is then cumbersome. The qualtRics R package implements the retrieval of survey data using the Qualtrics API and aims to reduce the pre-processing steps needed in analyzing such surveys. This package has been a huge help to me in my real day-to-day work, and I have been so grateful for the excellent work of the package's original authors, including the previous maintainer Jasper Ginn. This package is currently the only package on CRAN that offers functionality like this for Qualtrics' API, and is included in the official Qualtrics API documentation. The previous maintainer of this package was no longer using Qualtrics in his work life and needed to step away from maintaining qualtRics. Also, early in 2018, the package had been archived on CRAN for a fairly minor issue: using testthat for tests but not having it included in Qualtrics and the Stack Overflow Developer SurveyThe timing of when I did the usability work for this package was either wonderful or terrible, depending on your perspective. I did that work concurrently with the analysis for the 2019 Stack Overflow Developer Survey. This survey is the largest and most comprehensive survey of people who code around the world each year, and this year we had almost 90,000 respondents who answered questions covering everything from their favorite technologies to what music they listen to while coding. The survey is fielded using Qualtrics and I've used the qualtRics package for the past several years as part of my workflow. This year, I made changes to the package while I was working with the Developer Survey data. I'll be honest; it was… A LOT to juggle at one time. After the bulk of my analysis work was done for the survey, I turned to getting qualtRics back on CRAN. The previous maintainer, who has been unfailingly helpful throughout this process, sent an email to CRAN with the details involved (his name, my name, the fact of the package's archiving). Then I submitted the package to CRAN, basically as if it were a new package. I got some feedback back from CRAN initially, to use more single quotes in GOOD IDEA/BAD IDEAChanging the names of all the functions in a package already being used in the real world is, generally, a bad idea. I did it anyway, everybody. Let me try to convince you that this was the right call.
The old versions of the functions currently still work but give a warning, suggesting that the user try out the new versions. If this change causes more than a passing inconvenience to you as a user, I AM SO SORRY. I believe this decision will set up the qualtRics package for improved usability in the long term. Explore the new qualtRics!Another change with this release is a pkgdown site for qualtRics. I used the custom pkgdown template rotemplate created for rOpenSci packages to style the site, and I am so pleased with the results! If you are a new user for the qualtRics package, or someone who wants to poke around and see what's changed and how to get up to speed with the update, I recommend checking out this spiffy new site for all the details.
To leave a comment for the author, please follow the link and comment on their blog: rOpenSci - open tools for open science. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| What matters more in a cluster randomized trial: number or size? Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on ouR data generation, and kindly contributed to R-bloggers) I am involved with a trial of an intervention designed to prevent full-blown opioid use disorder for patients who may have an incipient opioid use problem. Given the nature of the intervention, it was clear the only feasible way to conduct this particular study is to randomize at the physician rather than the patient level. There was a concern that the number of patients eligible for the study might be limited, so that each physician might only have a handful of patients able to participate, if that many. A question arose as to whether we can make up for this limitation by increasing the number of physicians who participate? That is, what is the trade-off between number of clusters and cluster size? This is a classic issue that confronts any cluster randomized trial – made more challenging by the potentially very small cluster sizes. A primary concern of the investigators is having sufficient power to estimate an intervention effect – how would this trade-off impact that? And as a statistician, I have concerns about bias and variance, which could have important implications depending on what you are interested in measuring. Clustering in a nutshellThis is an immense topic – I won't attempt to point you to the best resources, because there are so many out there. For me, there are two salient features of cluster randomized trials that present key challenges. First, individuals in a cluster are not providing as much information as we might imagine. If we take an extreme example of a case where the outcome of everyone in a cluster is identical, we learn absolutely nothing by taking an additional subject from that cluster; in fact, all we need is one subject per cluster, because all the variation is across clusters, not within. Of course, that is overly dramatic, but the same principal is in play even when the outcomes of subjects in a cluster are moderately correlated. The impact of this phenomenon depends on the within cluster correlation relative to the between cluster correlation. The relationship of these two correlations is traditionally characterized by the intra-class coefficient (ICC), which is the ratio of the between-cluster variation to total variation. Second, if there is high variability across clusters, that gets propagated to the variance of the estimate of the treatment effect. From study to study (which is what we are conceiving of in a frequentist frame of mind), we are not just sampling individuals from the clusters, but we are changing the sample of clusters that we are selecting from! So much variation going on. Of course, if all clusters are exactly the same (i.e. no variation between clusters), then it doesn't really matter what clusters we are choosing from each time around, and we have no added variability as a result of sampling from different clusters. But, as we relax this assumption of no between-cluster variability, we add over-all variability to the process, which gets translated to our parameter estimates. The cluster size/cluster number trade-off is driven largely by these two issues. SimulationI am generating data from a cluster randomized trial that has the following underlying data generating process: \[ Y_{ij} = 0.35 * R_j + c_j + \epsilon_{ij}\ ,\] Defining the simulationThe entire premise of this post is that we have a target number of study subjects (which in the real world example was set at 480), and the question is should we spread those subjects across a smaller or larger number of clusters? In all the simulations that follow, then, we have fixed the total number of subjects at 480. That means if we have 240 clusters, there will be only 2 in each one; and if we have 10 clusters, there will be 48 patients per cluster. In the first example shown here, we are assuming an ICC = 0.10 and 60 clusters of 8 subjects each: Generating a single data set and estimating parametersBased on the data definitions, I can now generate a single data set: We use a linear mixed effect model to estimate the treatment effect and variation across clusters: Here are the estimates of the random and fixed effects: And here is the estimated ICC, which happens to be close to the "true" ICC of 0.10 (which is definitely not a sure thing given the relatively small sample size): A deeper look at the variation of estimatesIn these simulations, we are primarily interested in investigating the effect of different numbers of clusters and different cluster sizes on power, variation, bias (and mean square error, which is a combined measure of variance and bias). This means replicating many data sets and studying the distribution of the estimates. To do this, it is helpful to create a functions that generates the data: And here is a function to check if p-values from model estimates are less than 0.05, which will come in handy later when estimating power: Now we can generate 1000 data sets and fit a linear fixed effects model to each one, and store the results in an R list: Extracting information from all 1000 model fits provides an estimate of power: And here are estimates of bias, variance, and root mean square error of the treatment effect estimates. We can see in this case, the estimated treatment effect is not particularly biased: And if we are interested in seeing how well we measure the between cluster variation, we can evaluate that as well. The true variance (used to generate the data), was 0.10, and the average of the estimates was 0.099, quite close: Replications under different scenariosNow we are ready to put all of this together for one final experiment to investigate the effects of the ICC and cluster number/size on power, variance, and bias. I generated 2000 data sets for each combination of assumptions about cluster sizes (ranging from 10 to 240) and ICC's (ranging from 0 to 0.15). For each combination, I estimated the variance and bias for the treatment effect parameter estimates and the between-cluster variance. (I include the code in case any one needs to do something similar.) First, we can take a look at the power. Clearly, for lower ICC's, there is little marginal gain after a threshold between 60 and 80 clusters; with the higher ICC's, a study might benefit with respect to power from adding more clusters (and reducing cluster size):
Not surprisingly, the same picture emerges (only in reverse) when looking at the variance of the estimate for treatment effect. Variance declines quite dramatically as we increase the number of clusters (again, reducing cluster size) up to about 60 or so, and little gain in precision beyond that:
If we are interested in measuring the variation across clusters (which was \(\sigma^2_c\) in the model), then a very different picture emerges. First, the plot of RMSE (which is \(E[(\hat{\theta} – \theta)^2]^{\frac{1}{2}}\), where \(\theta = \sigma^2_c\)), indicates that after some point, actually increasing the number of clusters after a certain point may be a bad idea.
The trends of RMSE are mirrored by the variance of \(\hat{\sigma^2_c}\):
I show the bias of the variance estimate, because it highlights the point that it is very difficult to get an unbiased estimate of \(\sigma^2_c\) when the ICC is low, particularly with a large number of clusters with small cluster sizes. This may not be so surprising, because with small cluster sizes it may be more difficult to estimate the within-cluster variance, an important piece of the total variation.
Almost an addendumI've focused entirely on the direct trade-off between the number of clusters and cluster size, because that was the question raised by the study that motivated this post. However, we may have a fixed number of clusters, and we might want to know if it makes sense to recruit more subjects from each cluster. To get a picture of this, I re-ran the simulations with 60 clusters, by evaluated power and variance of the treatment effect estimator at cluster sizes ranging from 5 to 60. Under the assumptions used here, it also looks like there is a point after which little can be gained by adding subjects to each cluster (at least in terms of both power and precision of the estimate of the treatment effect):
To leave a comment for the author, please follow the link and comment on their blog: ouR data generation. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Compute R2s and other performance indices for all your models! Posted: 29 Apr 2019 05:00 PM PDT (This article was first published on R on easystats, and kindly contributed to R-bloggers)
Indices of model performance (i.e., model quality, goodness of fit, predictive accuracy etc.) are very important, both for model comparison and model description purposes. However, their computation or extraction for a wide variety of models can be complex. To address this, please let us introduce the performanceWe have recently decided to collaborate around the new easystats project, a set of packages designed to make your life easier (currently WIP). This project encompasses several packages, devoted for instance to model access or Bayesian analysis, as well as indices of model performance. The goal of
ExamplesMixed ModelsFirst, we calculate the r-squared value and intra-class correlation coefficient (ICC) for a mixed model, using r2() and icc(). Now let's compute all available indices of performance appropriate for a given model. This can be done via the model_performance(). Bayesian Mixed ModelsFor Bayesian mixed models, we have the same features available (r-squared, ICC, …). In this example, we focus on the output from
More details about Get InvolvedThere is definitely room for improvement, and some new exciting features are already planned. Feel free to let us know how we could further improve this package! To conclude, note that easystats is a new project in active development. Thus, do not hesitate to contact us if you want to get involved
To leave a comment for the author, please follow the link and comment on their blog: R on easystats. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... This posting includes an audio/video/photo media file: Download Now |
| Marketing with Machine Learning: Apriori Posted: 29 Apr 2019 04:05 PM PDT (This article was first published on R – Detroit Data Lab, and kindly contributed to R-bloggers) This is part 1 of an ongoing series, introduced in Detroit Data Lab Presents: Marketing with Machine Learning Introduction Apriori, from the latin "a priori" means "from the earlier." As with many of our predictions, we're learning from the past and applying it toward the future. It's the "Hello World" of marketing with machine learning! The simple application is growth in sales by identifying items that are commonly purchased together as part of a set by a customer, segment, or market. Talented marketers can power a variety of strategies with insights from this, including intelligent inventory management, market entry strategies, synergy identification in mergers & acquisitions, and much more. The Marketing with Machine Learning Starter Kit: A problem, a data specification, a model, and sample code. First, the problem we're solving. We all understand Amazon's "customers like you also purchased…" so let's branch out. In the example at the bottom, we're looking to help shape our market strategy around a key client. This tactic would be particularly useful as part of an account-based marketing strategy, where a single client is thought of as a "market of one" for independent analysis. We'll pretend your business has gone to great lengths to understand where one of your customers sources all of its materials, and mapped it out accordingly. You want to understand your opportunity for expansion. If this customer purchases services X from other customers, are there other strongly correlated services? You could be missing out on an opportunity to land more business, simply by not knowing enough to ask. We move on to the data specification. There are two best ways to receive this data. The long dataset, or "single" dataset, looks like this: The wide dataset, or the "basket" dataset, looks like this: CSV's, as usual, are the typical way these are transferred. Direct access to a database or system is always preferred, since we want to tap into pre-existing data pipelines where necessary so it's already cleaned and scrubbed of any sensitive information. Next, the model to use. In this case, we're interested in determining the strength of association between purchasing service X and any other services, so we've selected the apriori algorithm. The apriori algorithm has 3 key terms that provide an understanding of what's going on: support, confidence, and lift. Support is the count of how often items appear together. For example, if there are 3 purchases:
Then we say the support for pen + paper is 2, since the group occurred two times. Confidence is essentially a measure of how much we believe product will follow, once we know product X is being purchased. In the example above, we would say that buying pen => buying paper has confidence of 66.7%, since there are 3 transactions with a pen, and 2 of them also include paper. Lift is the trickiest one. It's the ratio of your confidence value to your expected confidence value. It often is considered the importance of a rule. Our lift value for the example above is (2/3) / ((3/3) * (2/3)) or 1. A lift value of 1 is actually uneventful or boring, since what it tells us is that the pen is very popular, and therefore the paper purchase probably has nothing to do with the pen being in the transaction. A lift value of greater than 1 implies some significance in the two items, and warrants further investigation. Finally, the code you can use. To keep the introduction simple, we're using R with only a few packages, and nothing more sophisticated than a simple CSV. Using the Detroit Business Certification Register from the City of Detroit, we'll interpret it as a consumption map. This dataset, with its NIGP Codes, provides us with a transactional set of all categories a business is in. ## Apriori Demonstration code # Loading appropriate packages before analysis library(tidyr) library(dplyr) library(stringr) library(arules) # Read in the entire Detroit Business Register CSV dfDetBusiness <- read.csv("Detroit_Business_Certification_Register.csv") # Prepare a new data frame that puts each NIGP code in its own row, by business dfCodes <- dfDetBusiness %>% mutate(Codes = strsplit(as.character(NIGP.Codes),",")) %>% unnest(Codes) %>% select(Business.Name, Codes) # Some rows appear with a decimal place. Strip out the decimal place. dfCodes$Codes <- str_remove(dfCodes$Codes, "\\.0") # Also trim the whitespace from any codes if it exists dfCodes$Codes <- trimws(dfCodes$Codes) # Write the data write.csv(dfCodes, file = "TransactionsAll.csv", row.names = FALSE) # Import as single with arule objTransactions <- read.transactions("TransactionsAll.csv", format = "single", skip = 1, cols = c(1,2)) # Glance at the summary; does it make sense? summary(objTransactions) # Relative frequency of top 10 items across all transactions itemFrequencyPlot(objTransactions,topN=10,type="relative") # Generate the association rules; maximum 4 items in a rule assoc.rules <- apriori(objTransactions, parameter = list(supp=0.001, conf=0.8,maxlen=4)) # Check out the summary of the object summary(assoc.rules) # View the top 25 rules inspect(assoc.rules[1:25]) By plotting the frequency, reviewing the summary of the association rules, and inspecting a few of the rows, a plan can begin to emerge on what actions to take. In this case, we find Rental Equipment (977) and Amusement & Decorations (037) always go together. Similarly, when Acoustical Tile (010) and Roofing Materials (077) are purchased, so are Elevators & Escalators (295). An odd combination! Conclusion With these insights uncovered, a marketer can begin to form a strategy. Do you develop a new product? Exit a specific market? Press on the customer to purchase more in a certain area from us, or a strategic partner? The possibilities are endless, but at least you're armed with knowledge to make the decision!
To leave a comment for the author, please follow the link and comment on their blog: R – Detroit Data Lab. R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: Data science, Big Data, R jobs, visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more... |











 However, it did allow me to test out improvements and changes iteratively with the real world data I had at hand, and I think I ended up with a better result than I would have otherwise. We use Qualtrics for other surveys at Stack Overflow throughout the year, so I am not just a package maintainer but also a year-round, real-life user of this package.
However, it did allow me to test out improvements and changes iteratively with the real world data I had at hand, and I think I ended up with a better result than I would have otherwise. We use Qualtrics for other surveys at Stack Overflow throughout the year, so I am not just a package maintainer but also a year-round, real-life user of this package. but I ended up responding via email and submitting again with the same text in CRAN comments, explaining those points. Fortunately, the package was accepted to CRAN that time!
but I ended up responding via email and submitting again with the same text in CRAN comments, explaining those points. Fortunately, the package was accepted to CRAN that time!









| You are subscribed to email updates from R-bloggers. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
Comments
Post a Comment